
De Datasnelweg: Set-oriented data verwerken in SQL
Als we de database laten doen waar deze het beste in is, kunnen we ook bij grote batches zorgen voor een snelle verwerking van onze data.

Het probleem
Data speelt een steeds belangrijkere rol in onze samenleving: Google, Twitter, Facebook en nog vele andere bedrijven verzamelen enorme hoeveelheden data over hun gebruikers. De verzamelde data gebruiken ze bijvoorbeeld voor advertentie doeleinden. Bij DSW verwerken we ook grote hoeveelheden data in een keer, maar dan met andere doeleinden. Denk bijvoorbeeld aan wanneer een groot ziekenhuis zijn declaraties indient. Duizenden regels moeten op zo’n moment in worden ingelezen en opgeslagen. Wanneer dit niet tijdig lukt lopen we het risico dat de hele keten ophoopt, wat kan resulteren in achterstallige betalingen. Het is dus belangrijk dat het opslaan van deze data aan onze kant zo snel mogelijk gebeurt.
De standaard methode die je op internet vindt, en ook door veel frameworks wordt gebruikt, is het één voor één opslaan van objecten. Deze methode is row-oriented. Bij een miljoen objecten kan dit erg lang duren. Wanneer een proces moet wachten op een specifiek punt, kan dit zelfs de hele keten ophouden. Als organisatie waar dit soort processen continu draaien willen we dit zoveel mogelijk voorkomen.
Een oplossing
Een oplossing voor dit probleem is om alle data in één keer aan de database te geven. De database doet dan waar deze het beste in is: een set aan data verwerken. Deze methode is dan ook set-oriented. Wanneer we vanuit de code de data als een tabel aanleveren aan de database kunnen we een merge-statement uitvoeren. Een merge-statement is ervoor bedoeld om twee tabellen samen te voegen. De uitdaging was om dit statement correct om te laten gaan met de insert, update en delete functionaliteit en daarnaast ook te controleren dat de data die eventueel aangepast werd ook aangepast mocht worden.
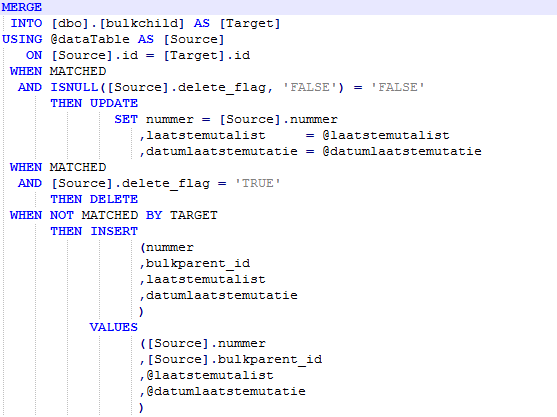
In de merge statement wordt de meegegeven datatabel vergeleken met de source datatabel. Aan de hand van een aantal condities wordt bepaald welke acties moeten worden uitgevoerd. De output van de uitgevoerde actie wordt tijdelijk bijgehouden in een outputtabel. Deze tijdelijke outputtabel is nodig, omdat aan het einde van de merge ook alle verwerkte data met de uitgevoerde actie dient te worden teruggegeven.
Codegeneratie
De C# en SQL code wil je niet voor elk object zelf moeten uitschrijven. Dit is tijd consumerend en foutgevoelig. Om deze problemen te voorkomen maken we gebruik van codegeneratie. Een voordeel hiervan is dat je de code slechts één keer hoeft te testen, en dat het eenvoudig is om van verschillende objecten de code te genereren. Een voordeel binnen DSW is dat de standaard CRUD (Create, Read, Update en Delete-statements) al worden gegenereerd. Op deze basis hebben we verder ontwikkeld om ook de merge functionaliteit uit te werken. Hieruit kwam een module die eenvoudig toe te voegen is. We hebben gekozen voor een losse module omdat deze functionaliteit niet overal nodig is, maar wanneer je het wel nodig hebt, je niet wilt dat het impact heeft op de bestaande code.
Data-analyse
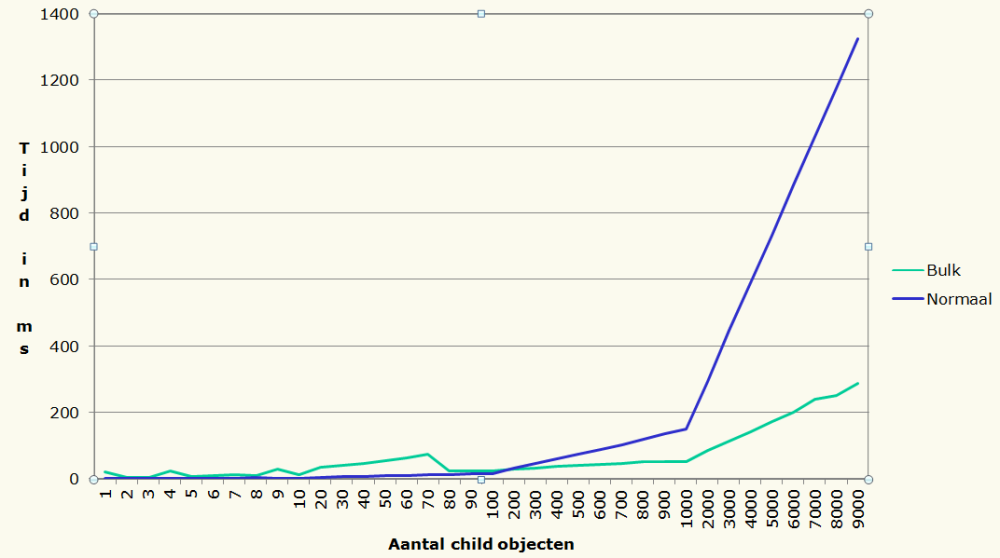
Vermelden dat je een verbetering ontwikkeld hebt is natuurlijk leuk, maar zonder een goede onderbouwing zegt het nog niks. De computer heeft voor een aantal dagen tests uitgevoerd om genoeg data te verzamelen. Dat de eerste set aan tests zo lang duurde was omdat elke test 90 keer werd uitgevoerd. Wanneer één test een paar miljoen records gaat verwerken en dit 90 keer moet doen kan dit tijdrovend worden, vooral als alle tests ook op de oude manier moeten worden uitgevoerd. Een voorbeeld van de verkregen data is hieronder in een tabel gerepresenteerd, wat mij betreft spreekt deze voor zich!
Conclusie
Door gebruik te maken van het set georiënteerde aspect van de SQL database konden we vooral op grote aantallen een enorme winst boeken in performance. Dit helpt ons verder om het gehele proces sneller te laten verlopen én om te voorkomen dat er op plekken onnodig bottlenecks ontstaan. Daarom zetten we deze methode nu al op verschillende projecten in.